用python分析关键词的出现频次
Danica 1/15/2022 爬虫
# 数据结构
从某招聘网站手动抓取了某区域前端岗位的JSON数据,打算来分析一下2022年该区域公司对前端岗位的技术需求。

抓取到的数据结构如下所示:
[
{
"jobName": "****",
"salaryDesc": "10-15K·13薪",
"jobLabels": [
"1-3年",
"本科"
],
"skills": [
"TypeScript",
"HTML",
"HTML5",
"AngularJS",
"Angular"
],
"jobExperience": "1-3年",
},
{
//内容
},
{
//内容
},
...
]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
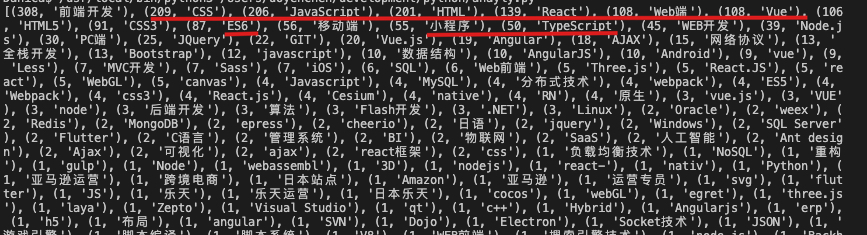
目标:统计skills里的各个技术出现的次数
# 配置
- 导入库
import json
import operator
1
2
2
创建变量
rank接收排序结果rank = []用
open方法打开json文件,用json.load方法读取数据,并用data接收
f = open('文件路径/文件名')
data = json.load(f)
1
2
2
4.创建变量frenquency_word,储存所有出现的关键词;变量count储存出现的次数。然后用for遍历循环json列表。
frequency_list = []
frequency_word = []
for i in data:
for keyword in i['skills']:
//关键词首次出现时添加到frenquency_word,然后count+1
if keyword not in frequency_word:
frequency_word.append(keyword)
count.append(1)
//关键词已经存在时,直接找到该关键词对应的index,然后count列表对应的位置也加1
else:
ind = frequency_word.index(keyword)
count[ind] += 1
f.close()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 合并frequency_word和count两个列表,用
rank接收后,使用operator模块的itemgetter函数辅助对二维列表进行按次数的倒序排序。
rank = list(zip(count,frequency_word))
rank.sort(key=operator.itemgetter(0),reverse=True)
1
2
2
以下是得出来的结果,html和css分别是第一第二,然后是js,react,vue,小程序和ts。node.js和jquery比想象中的少。